
- This topic has 9 replies, 6 voices, and was last updated 4 years, 4 months ago by
 Navinee Kruahong.
Navinee Kruahong.
-
AuthorPosts
-
-
2021-09-29 at 9:55 am #31700
 Pimphen CharoenKeymaster
Pimphen CharoenKeymasterFeel free to leave us questions in the forum below if you can’t make it on the day and we will response them during the session.
-
2021-10-05 at 3:23 pm #31859
 Jarunee Siengsanan-LamontParticipant
Jarunee Siengsanan-LamontParticipantSawasdee ka,
Have you emailed the meeting link? or how can I join the meeting tomorrow?
thank you very much in advance, Jar -
2021-10-05 at 9:55 pm #31871
 Rawinan SomaParticipant
Rawinan SomaParticipantDear all,
I have some questions about the evaluation of the models. I found some articles talk about “Precision” and “Recall” for classification model. What are these measurement, what are those tell about the model and difference from accuracy and error rate.
Thanks in advance,
Rawinan-
2021-10-07 at 7:58 pm #31955
 Pimwadee ChaovalitKeymaster
Pimwadee ChaovalitKeymasterDear Rawinan,
Thanks for your question. Accuracy is the percentage of correct prediction, while error rate is the percentage of the incorrect prediction. Those two numbers are calculated across all classes. Precision tells you how correct the algorithm was in predicting the positive class. Finally, recall tells you how much of the actual positive cases that the algorithm was able to predict as positive. I also did answer in Thai during the session so you may check out the video recording of the class meeting.
Pimwadee
-
-
2021-10-17 at 10:08 am #32215Navinee KruahongParticipant
I have a question about the value of between SS and total SS.
between_SS / total_SS – This can tell us how good the clustering is. We want high between_SS / total_SS percentage but do we have a criteria to tell which % is high or low?Thank you in advance!
-
2021-10-18 at 10:32 am #32236Pimwadee ChaovalitKeymaster
Hi Navinee,
That is a good question. The short answer is there is no agreeable number in the industry as to which between_SS / total_SS is considered high or low. But let me take you through some examples, which I found on this link. It is helpful to consider between_SS / total_SS altogether with some plots of the data.
Now please consider case 1. This clustering yields between_SS / total_SS to be 47.5%. And the plot is displayed below.
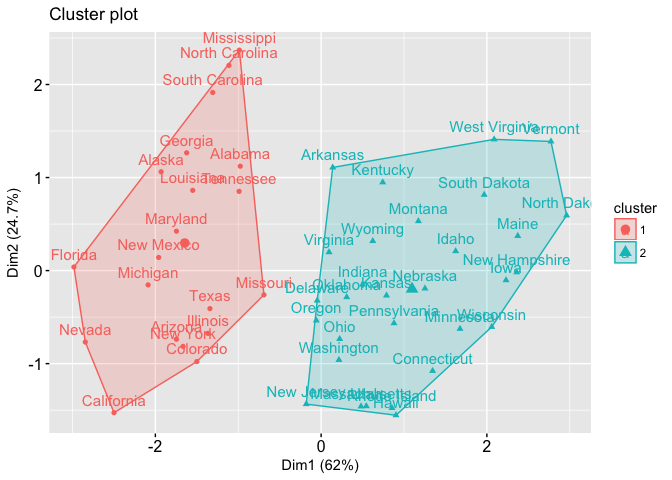
Whereas in case 2, you get between_SS / total_SS to be 71.2 %. Below is the plot of the second case.
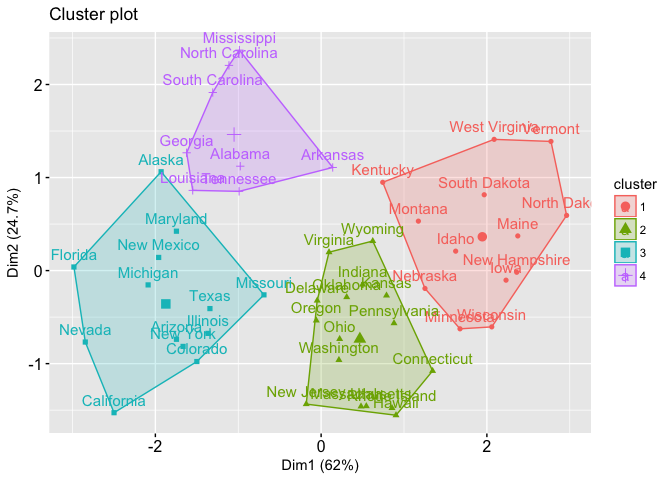
In the first case, 47.5% shows a good enough result, the clusters are somewhat separated. But I am not sure if we take the colors away from the plot we can still clearly see the clusters. Whereas in the second case, 71.2% shows more well-separated clusters (there’s more white space between clusters).
So in my opinion, if the between_SS / total_SS is over 70% I usually considered this very good, which means if I were to plot the data I will see the clusters nicely split. If my between_SS / total_SS is between 50-70%, I still consider this quite OK. I might want to verify the cluster qualities with other numbers and maybe with plots of data. But sometimes that’s as much as you can get out of your data. If my between_SS / total_SS is below 30%, then I think the result is not very good.
I hope this helps. If you have more questions, please let us know.
-
2021-10-23 at 10:25 pm #32324Navinee KruahongParticipant
Thank you so much! that really help!
-
-
-
2021-10-17 at 8:08 pm #32233
 Saravalee SuphakarnParticipant
Saravalee SuphakarnParticipantDear all staff,
I couldn’t access “Supplementary Reading: Decision Tree Result Evaluation in R”. I’m not sure about it cause from availability of the resource or it relate to my missing something from the class announcement. Please check it again. Thank you very much.
Saravalee S.
-
-
AuthorPosts
You must be logged in to reply to this topic. Login here